Forecasting Swiss ILI counts using `surveillance::hhh4`
Sebastian Meyer
2026-07-02
Source:vignettes/CHILI_hhh4.Rmd
CHILI_hhh4.Rmd
options(digits = 4) # for more compact numerical outputs
library("HIDDA.forecasting")
library("ggplot2")
source("setup.R", local = TRUE) # define test periods (OWA, TEST)In this vignette, we use forecasting methods provided by:
The corresponding software reference is:Hoehle M, Meyer S, Paul M (2026). surveillance: Temporal and Spatio-Temporal Modeling and Monitoring of Epidemic Phenomena. doi:10.32614/CRAN.package.surveillance. R package version 1.26.0, https://CRAN.R-project.org/package=surveillance.
Modelling
CHILI.sts <- sts(observed = CHILI,
epoch = as.integer(index(CHILI)), epochAsDate = TRUE)##
## 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015
## 52 52 52 52 53 52 52 52 52 53 52 52 52 52 52 53
## 2016
## 52
mean(weeksInYear)## [1] 52.18
## long-term average is 52.1775 weeks per year
f1 <- addSeason2formula(~ 1, period = 52.1775, timevar = "index")
## equivalent: f1 <- addSeason2formula(~ 1, period = 365.2425, timevar = "t")
hhh4fit <- hhh4(stsObj = CHILI.sts,
control = list(
ar = list(f = update(f1, ~. + christmas)),
end = list(f = f1),
family = "NegBin1",
data = list(index = 1:nrow(CHILI.sts),
christmas = as.integer(epochInYear(CHILI.sts) %in% 52))
))
summary(hhh4fit, maxEV = TRUE)##
## Call:
## hhh4(stsObj = CHILI.sts, control = list(ar = list(f = update(f1,
## ~. + christmas)), end = list(f = f1), family = "NegBin1",
## data = list(index = 1:nrow(CHILI.sts), christmas = as.integer(epochInYear(CHILI.sts) %in%
## 52))))
##
## Coefficients:
## Estimate Std. Error
## ar.1 -0.26854 0.03227
## ar.sin(2 * pi * index/52.1775) -0.15140 0.03429
## ar.cos(2 * pi * index/52.1775) 0.47004 0.04152
## ar.christmas -0.57122 0.12610
## end.1 5.32927 0.12010
## end.sin(2 * pi * index/52.1775) 0.30592 0.08390
## end.cos(2 * pi * index/52.1775) 0.54066 0.14252
## overdisp 0.19123 0.00898
##
## Epidemic dominant eigenvalue: 0.47 -- 1.25
##
## Log-likelihood: -6792
## AIC: 13599
## BIC: 13637
##
## Number of units: 1
## Number of time points: 886Alternatively, use a yearly varying frequency of 52 or 53 weeks for the sinusoidal time effects:
f1_varfreq <- ~ 1 + sin(2*pi*epochInYear/weeksInYear) + cos(2*pi*epochInYear/weeksInYear)
hhh4fit_varfreq <- update(hhh4fit,
ar = list(f = update(f1_varfreq, ~. + christmas)),
end = list(f = f1_varfreq),
data = list(epochInYear = epochInYear(CHILI.sts),
weeksInYear = rep(weeksInYear, weeksInYear)))
AIC(hhh4fit, hhh4fit_varfreq)## df AIC
## hhh4fit 8 13599
## hhh4fit_varfreq 8 13600
plot(hhh4fit, pch = 20, names = "", ylab = "")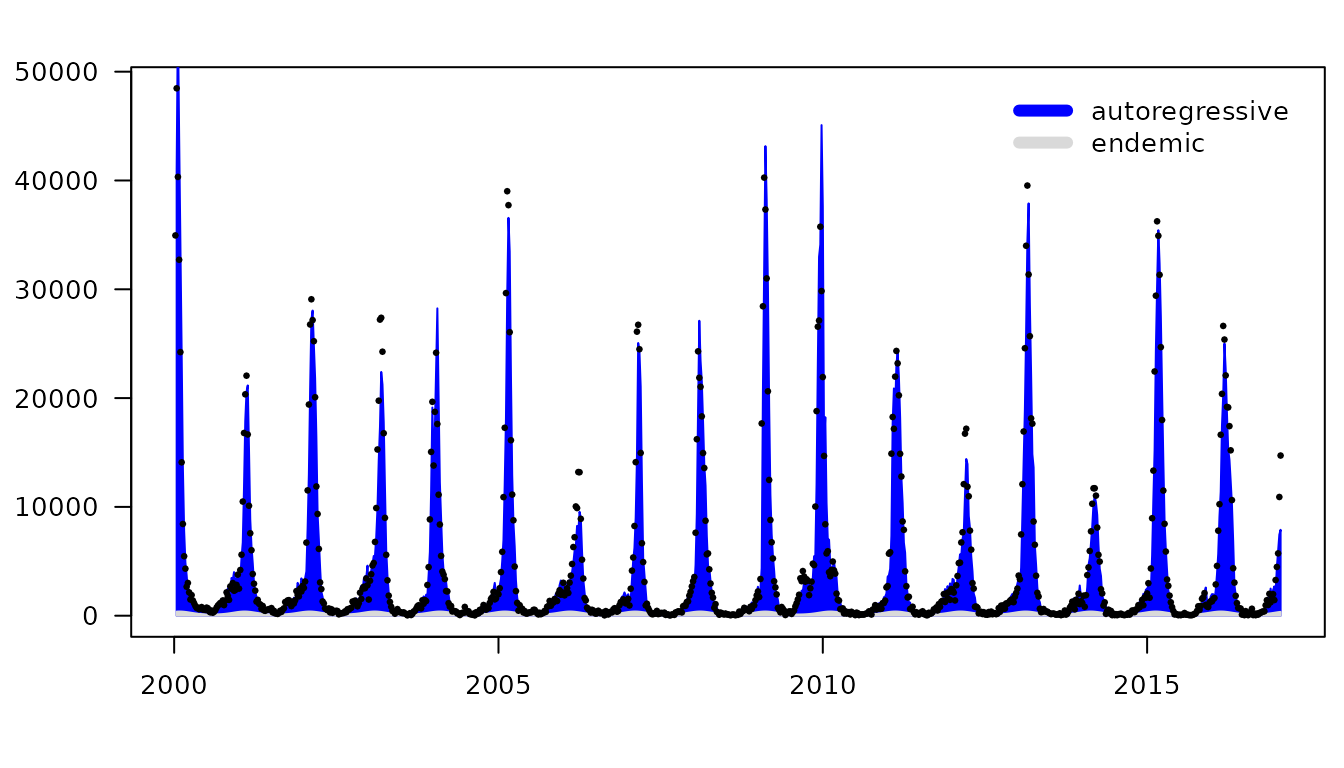
qplot(x = 1:53, y = drop(predict(hhh4fit, newSubset = 1:53, type = "ar.exppred")),
geom = "line", ylim = c(0,1.3), xlab = "week", ylab = expression(lambda[t])) +
geom_hline(yintercept = 1, lty = 2)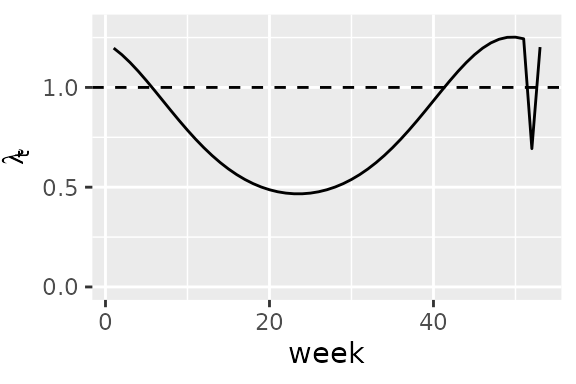
CHILIdat <- fortify(CHILI)
## add fitted mean and CI to CHILIdat
CHILIdat$hhh4upper <- CHILIdat$hhh4lower <- CHILIdat$hhh4fitted <- NA_real_
CHILIdat[hhh4fit$control$subset,"hhh4fitted"] <- fitted(hhh4fit)
CHILIdat[hhh4fit$control$subset,c("hhh4lower","hhh4upper")] <-
sapply(c(0.025, 0.975), function (p)
qnbinom(p, mu = fitted(hhh4fit),
size = exp(hhh4fit$coefficients[["-log(overdisp)"]])))
ggplot(CHILIdat, aes(x=Index, ymin=hhh4lower, y=hhh4fitted, ymax=hhh4upper)) +
geom_ribbon(fill="orange") + geom_line(col="darkred") +
geom_point(aes(y=CHILI), pch=20) +
scale_y_sqrt(expand = c(0,0), limits = c(0,NA))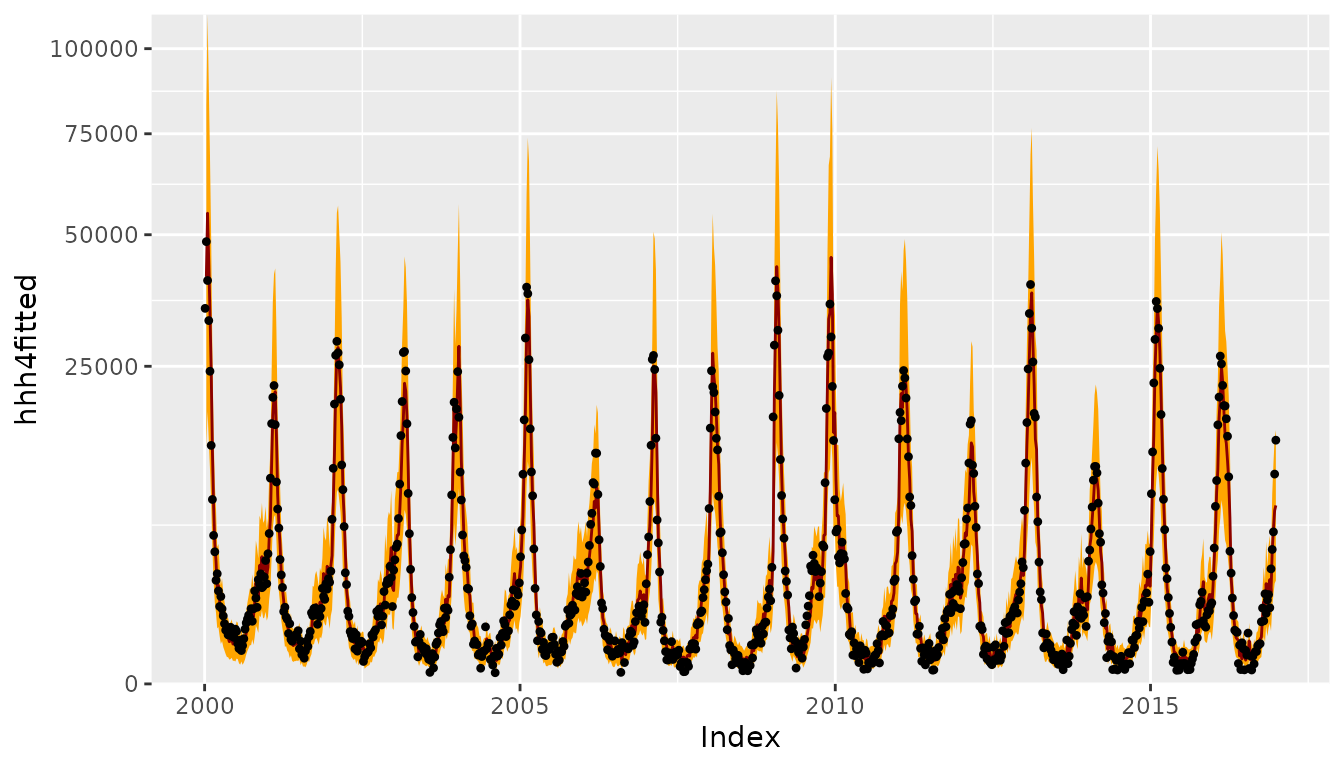
One-week-ahead forecasts
We compute 213 one-week-ahead forecasts from 2012-W48 to 2016-W51
(the OWA period), which takes roughly 4 seconds (we could
parallelize using the cores argument of
oneStepAhead()).
hhh4owa <- oneStepAhead(hhh4fit, range(OWA), type = "rolling", verbose = FALSE)
save(hhh4owa, file = "hhh4owa.RData")
calibrationTest(hhh4owa, which = "dss")##
## Calibration Test for Count Data (based on DSS)
##
## data: hhh4owa
## z = 0.74, n = 213, p-value = 0.5
## calibrationTest(hhh4owa, which = "logs") # skipped for CRAN
hhh4owa_scores <- scores(hhh4owa, which = c("dss", "logs"), reverse = FALSE)
summary(hhh4owa_scores)## dss logs
## Min. : 8.3 Min. : 4.98
## 1st Qu.:10.9 1st Qu.: 6.33
## Median :13.5 Median : 7.63
## Mean :13.6 Mean : 7.71
## 3rd Qu.:15.5 3rd Qu.: 8.85
## Max. :28.7 Max. :11.32
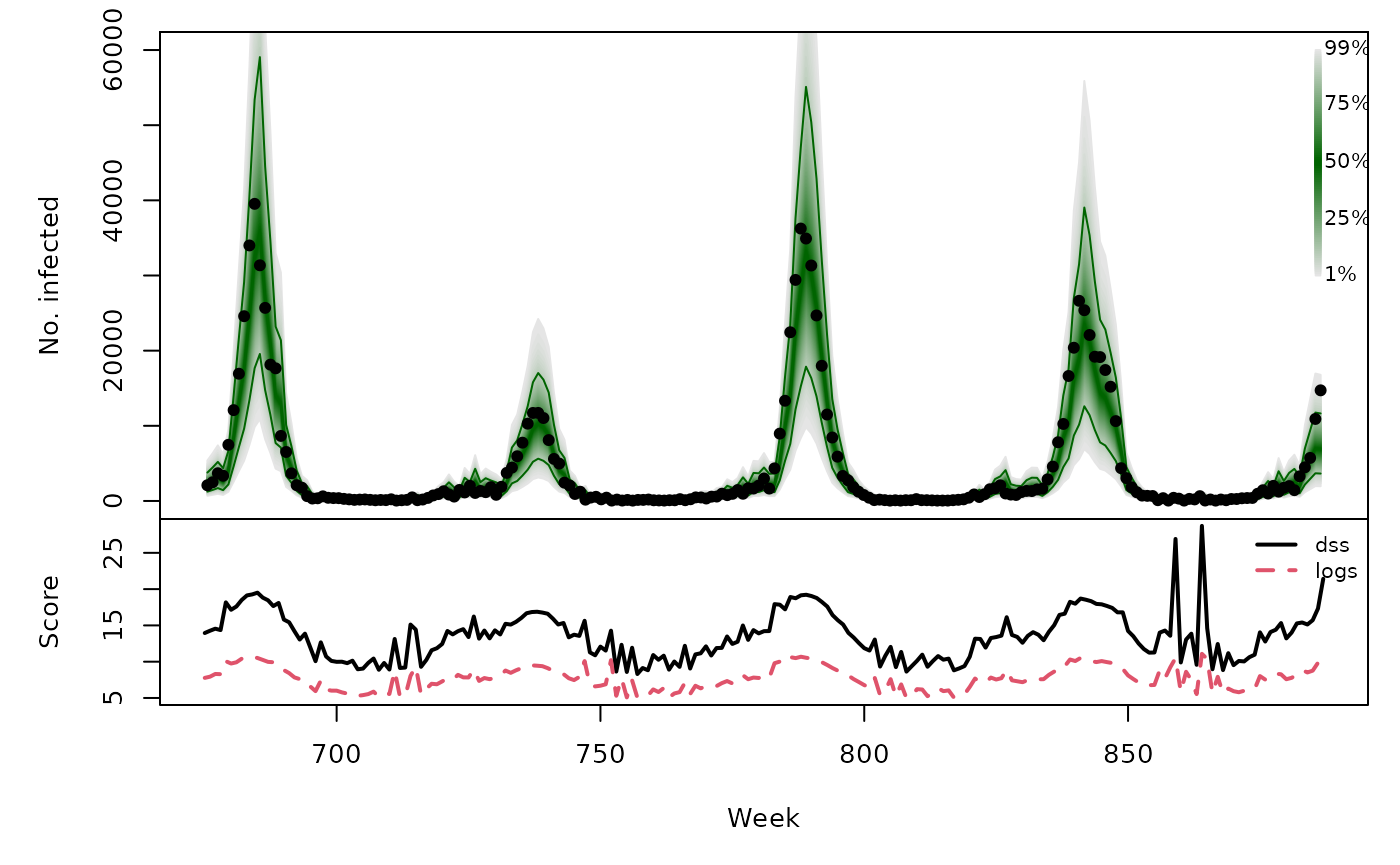
hhh4owa_quantiles <- quantile(hhh4owa, probs = 1:99/100)
osaplot(
quantiles = hhh4owa_quantiles, probs = 1:99/100,
observed = hhh4owa$observed, scores = hhh4owa_scores,
start = OWA[1]+1, xlab = "Week", ylim = c(0,60000),
fan.args = list(ln = c(0.1,0.9), rlab = NULL)
)
Long-term forecasts
Example with the first test period
TEST1 <- TEST[[1]]
fit1 <- update(hhh4fit, subset.upper = TEST1[1]-1)
hhh4sim1 <- simulate(fit1, nsim = 1000, seed = 726, subset = TEST1,
y.start = observed(CHILI.sts)[TEST1[1]-1,])We can use the plot method provided by surveillance:
par(mfrow=c(1,2))
plot(hhh4sim1, "fan", ylim = c(0,60000), xlab = "", ylab = "",
xaxis = list(xaxis.tickFreq = list("%m"=atChange, "%Y"=atChange),
xaxis.labelFreq = list("%Y"=atMedian),
xaxis.labelFormat = "%Y"))
plot(hhh4sim1, "size", horizontal = FALSE, main = "size of the epidemic",
ylab = "", observed = list(labels = NULL))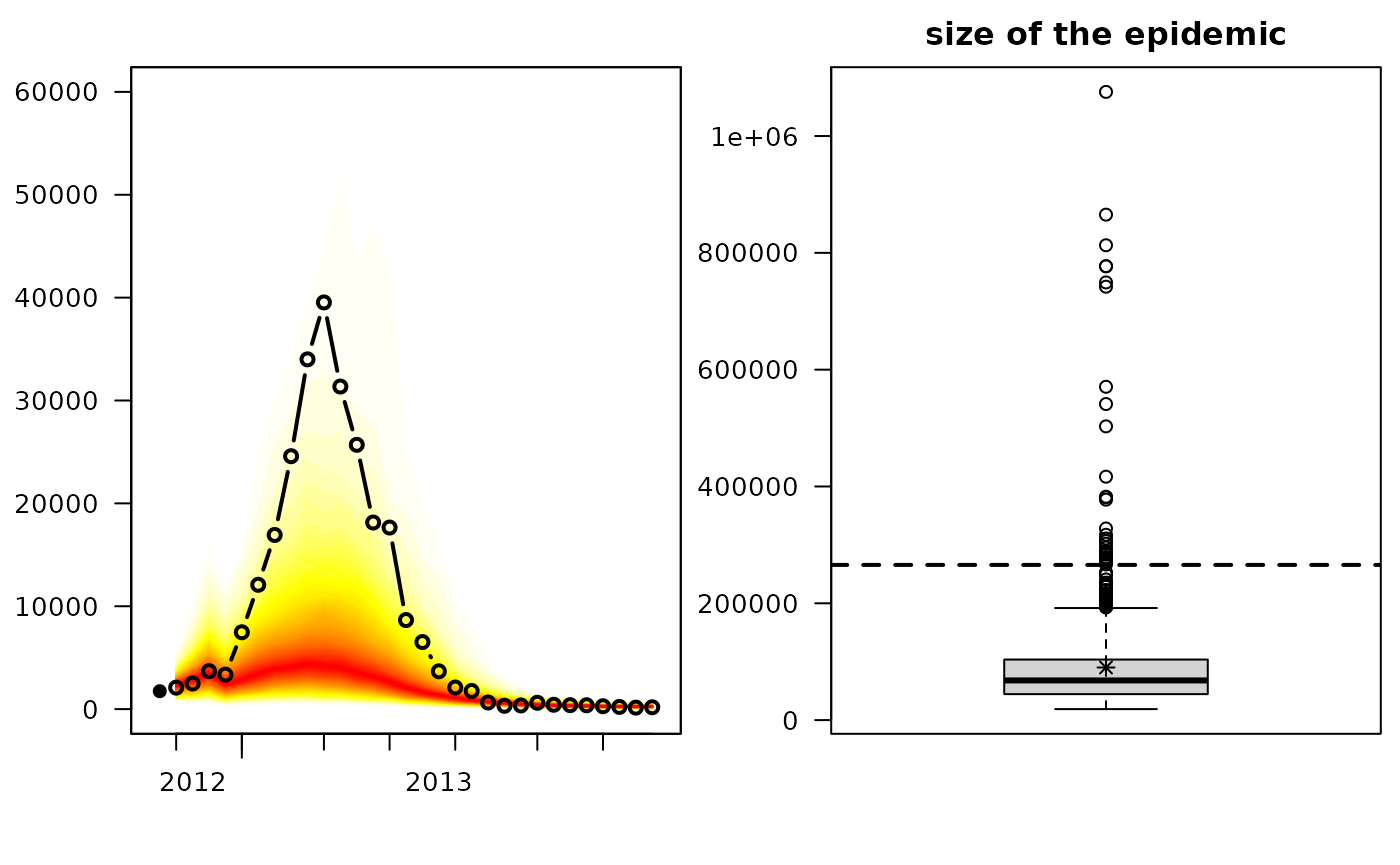
There is also an associated scores method:
## dss logs
## Min. :10.3 Min. :5.12
## 1st Qu.:11.8 1st Qu.:6.91
## Median :15.7 Median : Inf
## Mean :16.4 Mean : Inf
## 3rd Qu.:19.7 3rd Qu.: Inf
## Max. :29.2 Max. : InfUsing relative frequencies to estimate the forecast distribution from
these simulations is problematic. However, we can use kernel density
estimation as implemented in package scoringRules,
which the function scores_sample() wraps:
summary(scores_sample(x = observed(CHILI.sts)[TEST1], sims = drop(hhh4sim1)))## dss logs
## Min. :10.3 Min. : 5.68
## 1st Qu.:11.8 1st Qu.: 6.54
## Median :15.7 Median : 8.78
## Mean :16.4 Mean : 9.28
## 3rd Qu.:19.7 3rd Qu.:11.91
## Max. :29.2 Max. :14.55An even better approximation of the log-score at each time point can
be obtained by using a mixture of the one-step-ahead negative binomial
distributions given the samples from the previous time point. These
forecast distributions are available through the function
dhhh4sims(), which is used in
logs_hhh4sims():
summary(logs_hhh4sims(sims = hhh4sim1, model = fit1))## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 5.63 6.47 8.79 9.19 11.70 13.85For all test periods
hhh4sims <- lapply(TEST, function (testperiod) {
t0 <- testperiod[1] - 1
fit0 <- update(hhh4fit, subset.upper = t0)
sims <- simulate(fit0, nsim = 1000, seed = t0, subset = testperiod,
y.start = observed(CHILI.sts)[t0,])
list(testperiod = testperiod,
observed = observed(CHILI.sts)[testperiod],
fit0 = fit0, sims = sims)
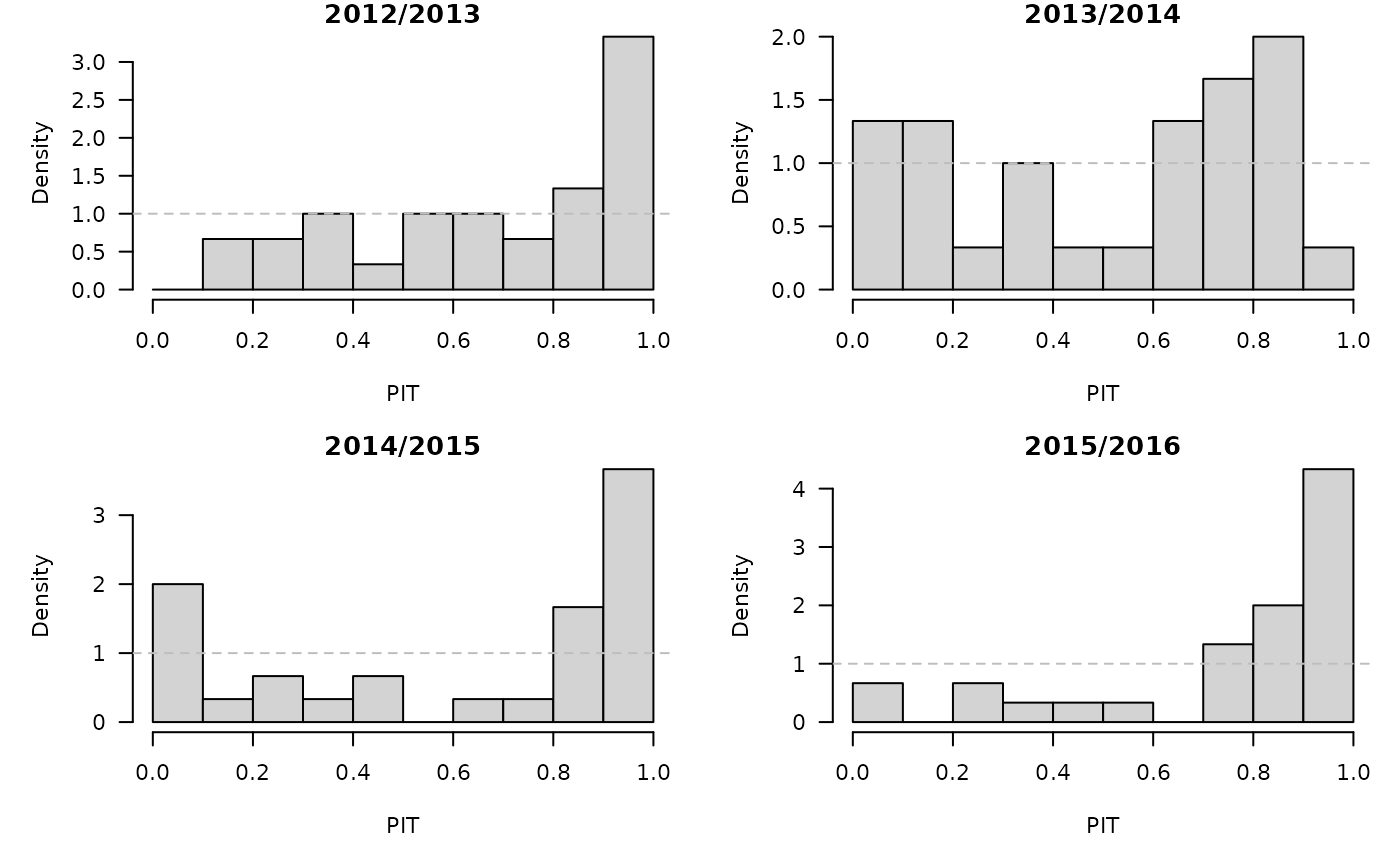
})PIT histograms, based on the pointwise ECDF of the simulated epidemic curves:
invisible(lapply(hhh4sims, function (x) {
pit(x = x$observed, pdistr = apply(x$sims, 1, ecdf),
plot = list(main = format_period(x$testperiod, fmt = "%Y", collapse = "/"),
ylab = "Density"))
}))
t(sapply(hhh4sims, function (x) {
quantiles <- t(apply(x$sims, 1, quantile, probs = 1:99/100))
scores <- scores_sample(x$observed, drop(x$sims))
## improved estimate via mixture of one-step-ahead NegBin distributions
## NOTE: we skip this here for speed (for CRAN)
##scores <- cbind(scores, logs2 = logs_hhh4sims(sims=x$sims, model=x$fit0))
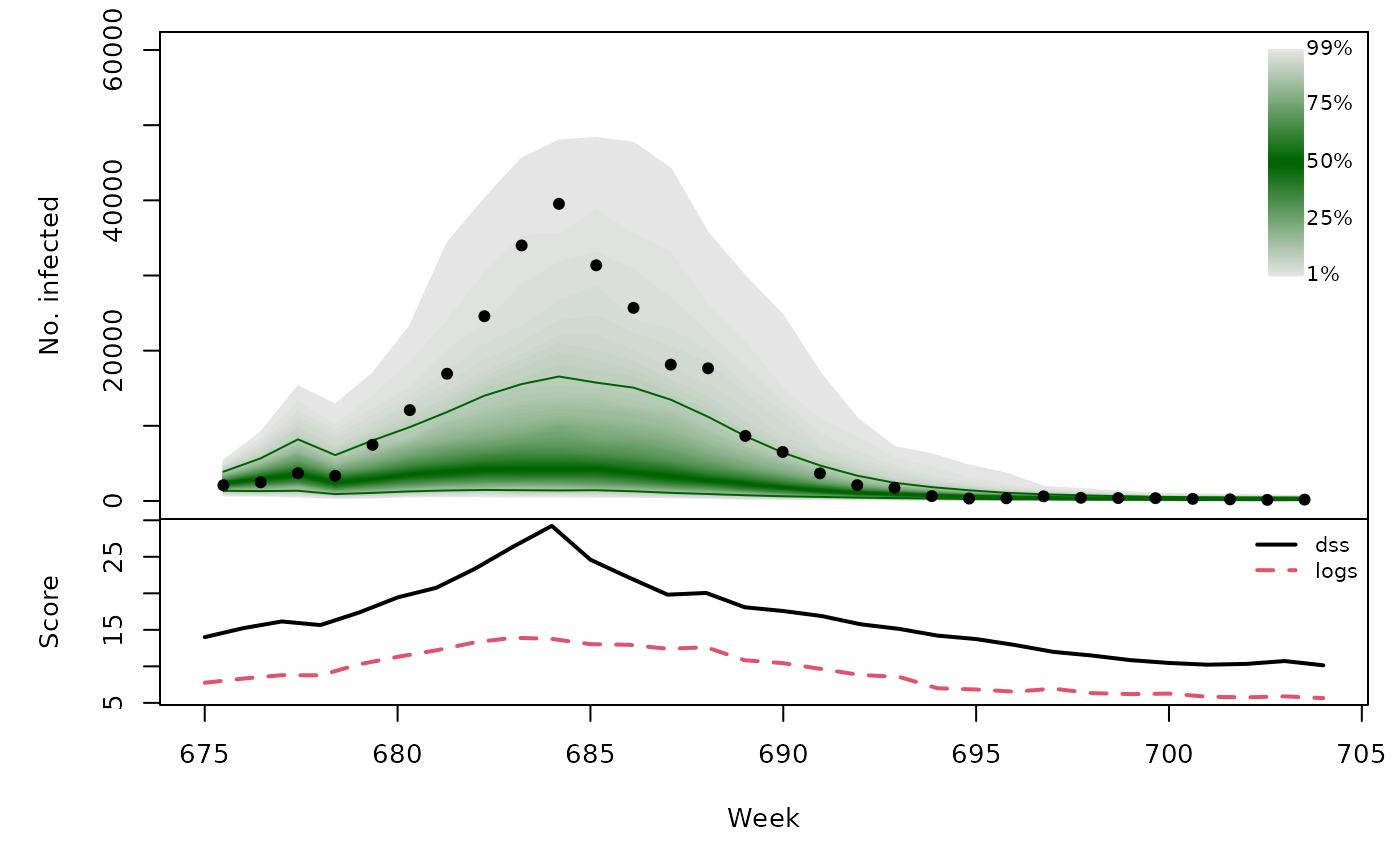
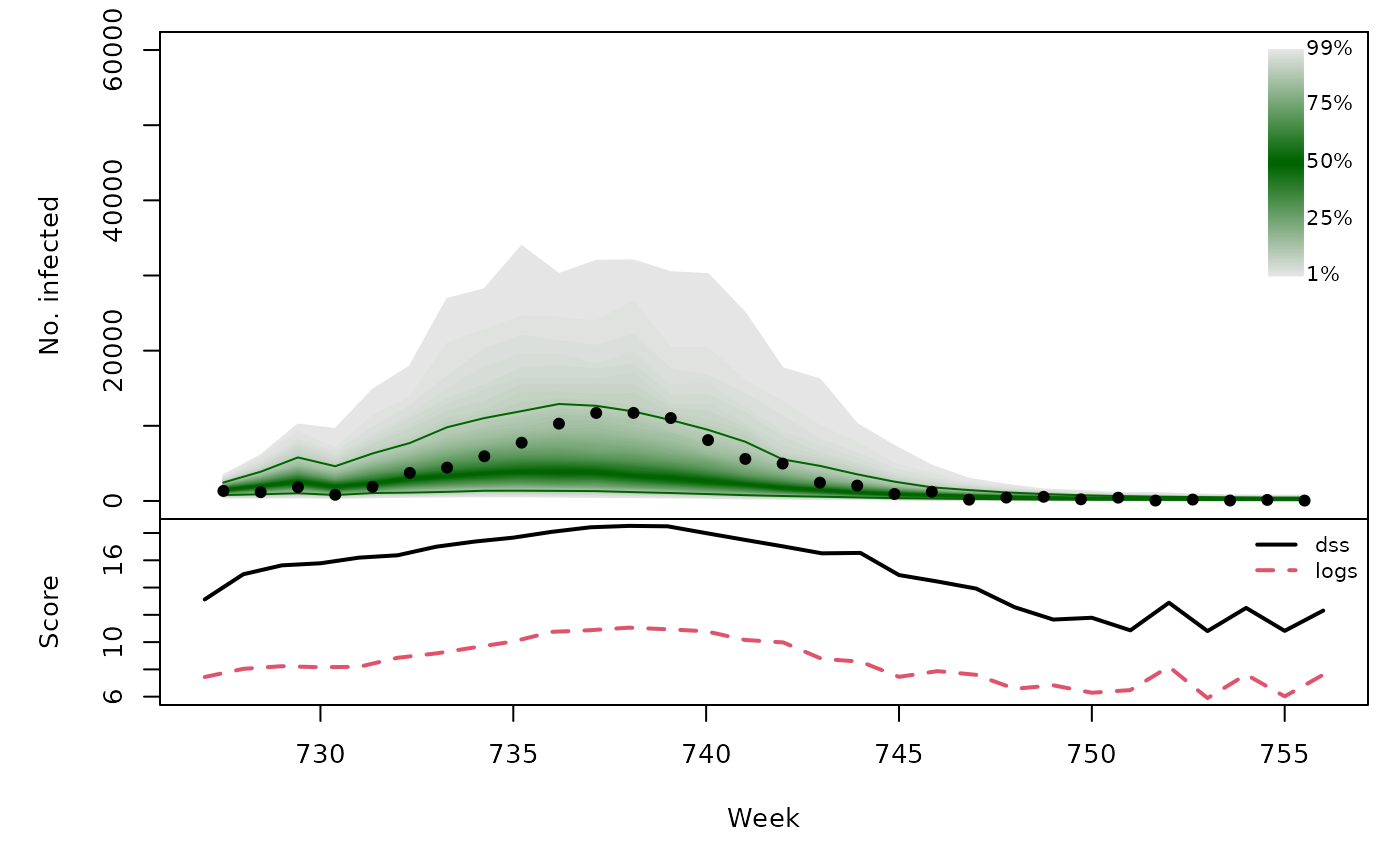
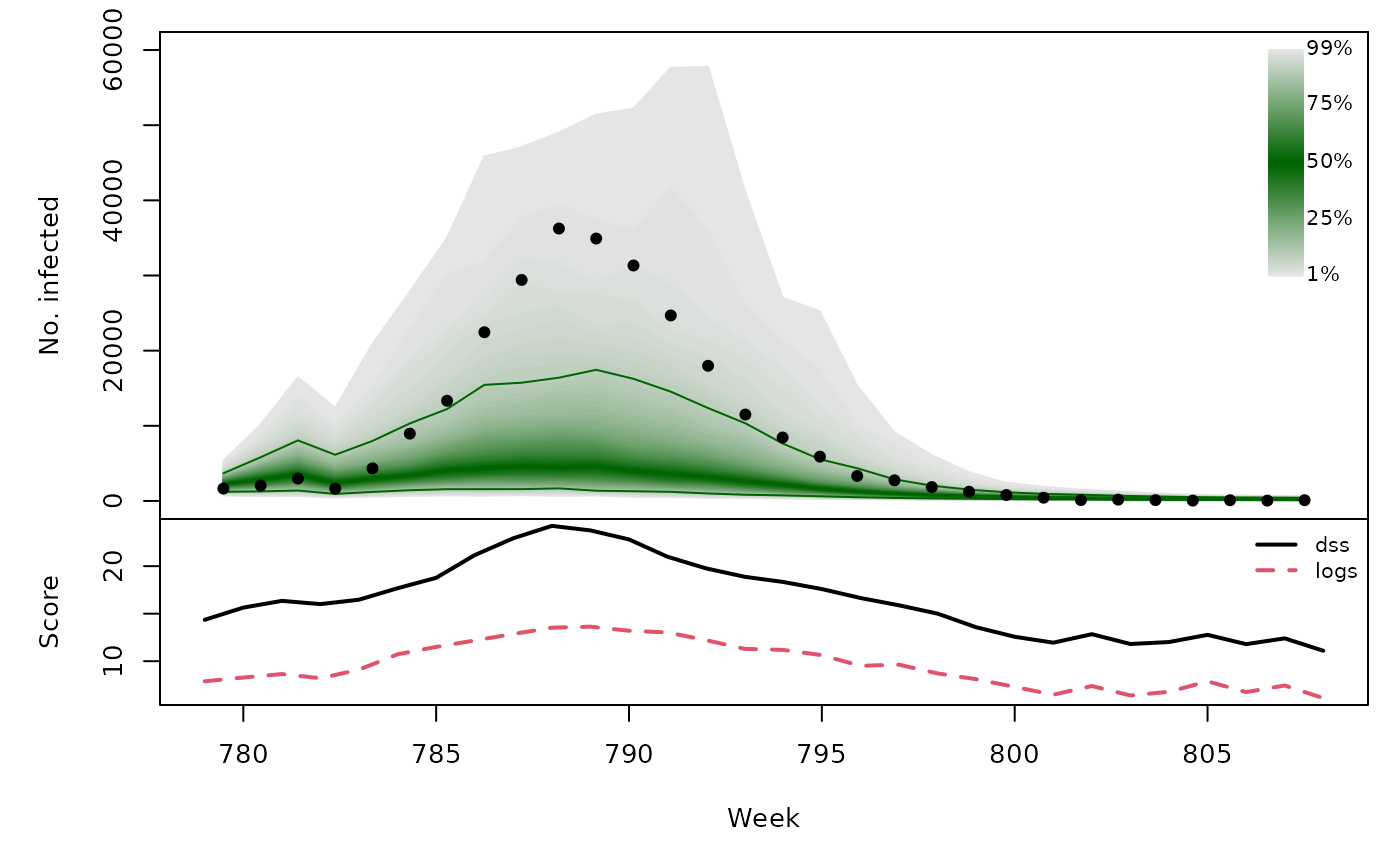
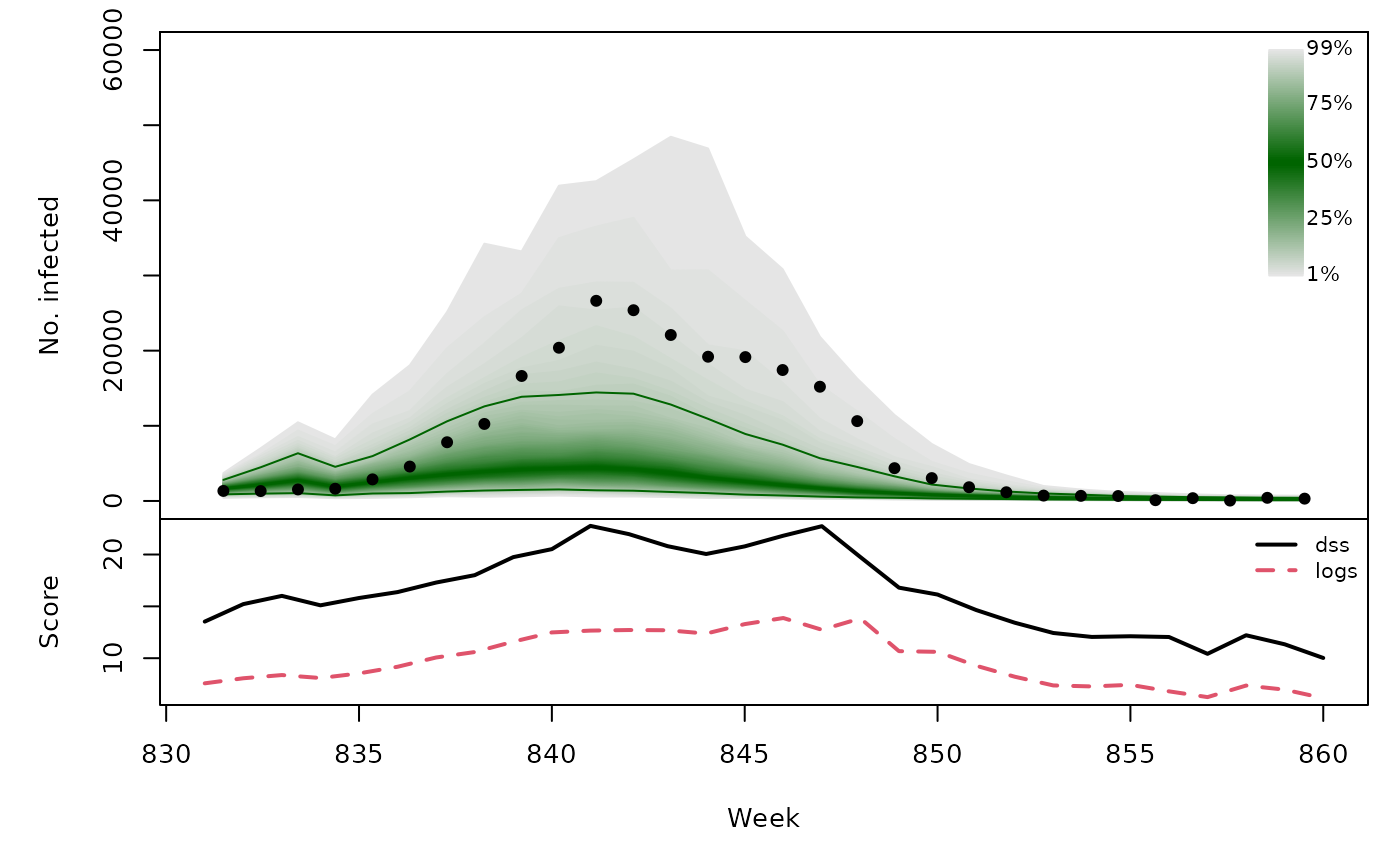
osaplot(quantiles = quantiles, probs = 1:99/100,
observed = x$observed, scores = scores,
start = x$testperiod[1], xlab = "Week", ylim = c(0,60000),
fan.args = list(ln = c(0.1,0.9), rlab = NULL))
colMeans(scores)
}))## dss logs
## [1,] 16.49 9.232
## [2,] 15.09 8.470
## [3,] 16.54 9.552
## [4,] 16.40 9.772